

전희성 교수님의 요청으로 작성된 포스트입니다. 많은 학생들에게 도움이 되었으면 합니다.
Unity를 아이폰용(ios)으로 빌드하는 방법을 알려드리겠습니다.
우선 Unity에서 이러한 작업을 수행하기 위해선 다음과 같은 조건이 필요합니다.
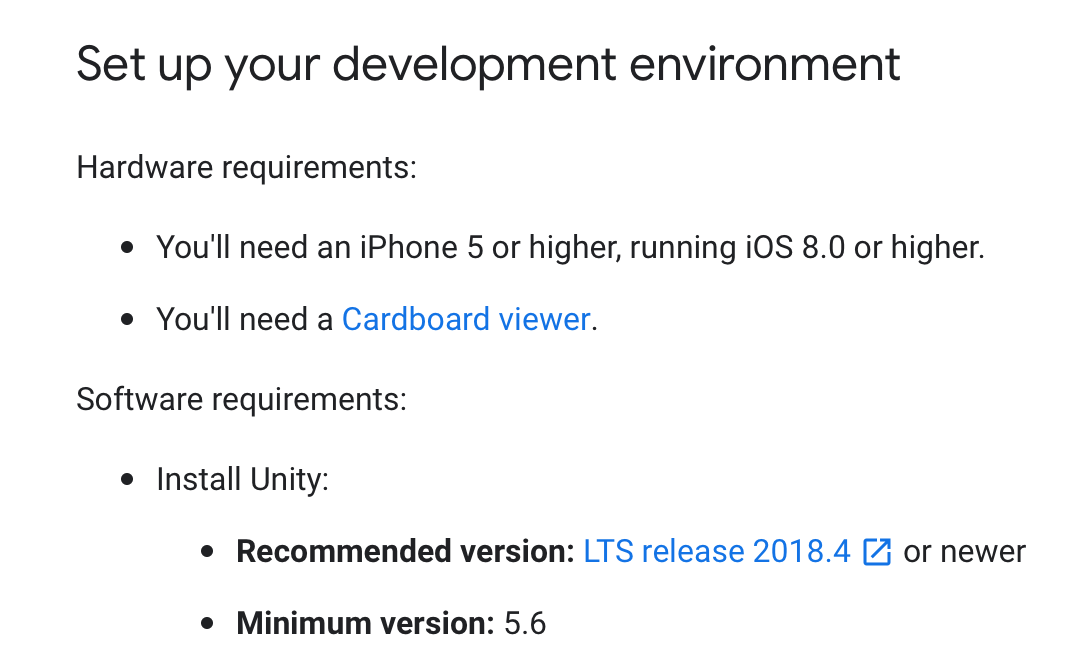
테스트 디바이스(아이폰)의 경우 ipone 5 이상이여야 하며, iOS의 버전은 8.0 이상이여야 합니다.
당연한 이야기지만 iphone 개발의 경우 Macbook이 무조건적으로 필요합니다...
mac이 없이 해킨토시로 어떻게든 하시려고 하는 분이 계신데 별로 추천 드리지 않습니다.
그냥 안드로이드 공기계를 구해서 안드로이드로 작업하시는 것이 정신건강에 좋을 것 같네요. (진심입니다)
그럼 설명을 진행하겠습니다.
Unity의 버전은 수업에서 사용하는 버전인 Unity 2019.1.15f1 을 사용합니다.
다만 안드로이드가 아닌 ios에서 작동되야 하므로 아래와 같이 체크를 해줍니다.

다음으로 프로젝트를 생성합니다. 간단하게 프로젝트명을 Cardboard로 지어주었습니다.

프로젝트를 열면 아래와 같은 화면이 표시 됩니다.

다음으로 GoogleVRForUnity파일을 받아와야 합니다.
github.com/googlevr/gvr-unity-sdk/releases
Releases · googlevr/gvr-unity-sdk
Google VR SDK for Unity. Contribute to googlevr/gvr-unity-sdk development by creating an account on GitHub.
github.com
위 링크에 접속하시면 최신 릴리즈 버전(2020년 11월 기준: 1.200.1)이 있습니다.
unitypackage파일을 다운로드 받아주세요.

다음으로 받은 unitypackage파일을 임포트 해주어야 합니다.
아래와 같이 Assets - Import Package - Custom Package 를 눌러 줍니다.

아까 다운로드 받아두었던 파일을 선택해 Open 버튼을 클릭합니다.

아래와 같이 패키지 임포트 파일의 체크 리스트가 표시됩니다.
다른 것 건드릴 필요없이 그대로 import 버튼을 눌러줍니다.

하단에 프로젝트 내 폴더 뷰창을 보시면 Assets 폴더 내에 GoogleVR 폴더가 성공적으로 임포트 되있는 것을 확인할 수 있습니다.

다음으로 Assets -> GoogleVR -> Prefabs 폴더에 들어가 GvrEditorEmulator.prefab 파일을 선택한 뒤,
Scene에 드래그 앤 드롭 방식으로 추가시켜줍니다.

다음으로 360도 파노라마 뷰가 가능한 이미지 파일을 임포트 해보겠습니다.
강의에서 사용하는 이미지 파일을 그대로 사용해보겠습니다.
해당 이미지는 아래 링크에서 받으실 수 있습니다.
pixexid.com/image/8hw0clw-360-panorama-miami
360 panorama miami free images
thet Curated by ਲਃਲਃਲਃਲਲਃਲਃਲਃਲਃਲਲਲਃਲਃਲ ਲਃਲਃਲਃਲਲਃਲਃਲਃਲਃਲਲਲਃਲਃਲ
pixexid.com
우측 상단에 Download 버튼을 눌러 다운로드 받아주세요.
다음으로 Unity에서 Assets -> Import New Asset을 클릭합니다.
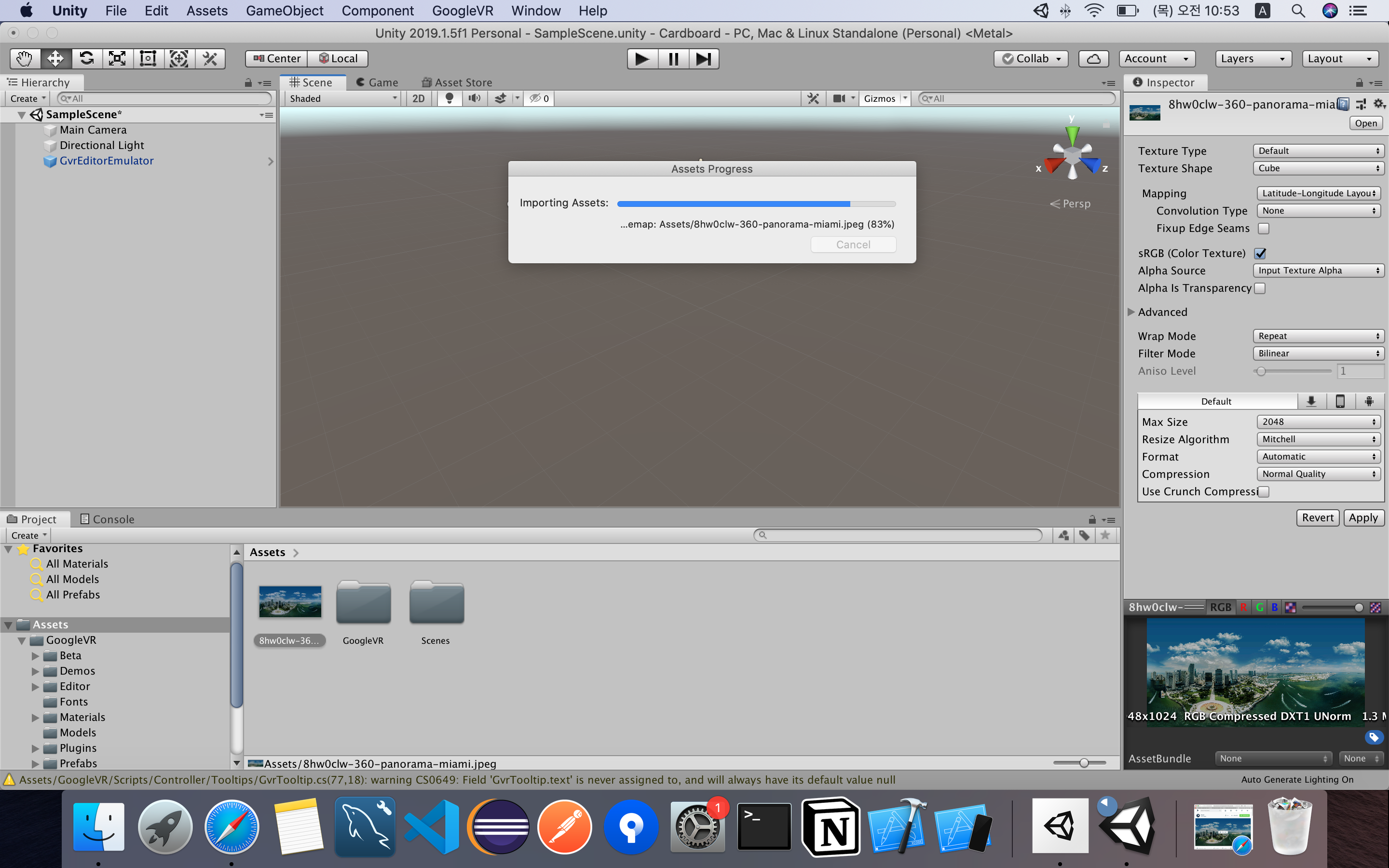
그 다음 받았던 이미지 파일을 임포트시켜 줍니다.

이미지 추가 후 아래와 같은 화면이 보여집니다.
아직까지는 딱히 어려운 것은 없네요

이미지 파일에 inspector에서 Texture Shape를 Cube로 Mapping 을 Latitude-Logitude Layout으로 변경해줍니다.
이후 아래와 같이 로딩이 진행됩니다.
로딩이 끝나면 평면이었던 이미지 파일이 구형 모양이 됩니다.

다음으로 Assets -> Create -> Material 을 클릭해 추가시켜 줍니다.

추가한 Material의 이름을 Sky로 변경해 줍니다.

해당 Material의 Shader를 Skybox/Cubemap으로 설정해줍니다.
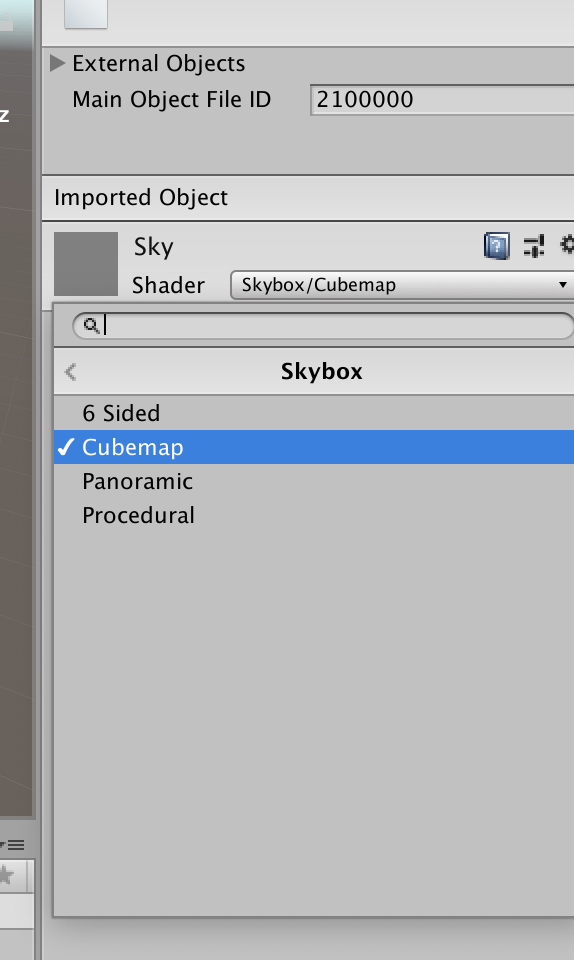
또한, Cubemap(HDR)에 있는 select를 눌러 아까 생성해두었던 구 모양의 파라노마 사진을 선택해줍니다.


위 작업이 끝났다면 아래와 같이 Sky meterial에 이미지가 적용되었음을 확인 할 수 있습니다.

위 Sky Meterial을 드래그 앤 드롭 방식으로 Scene 위에 올려줍니다.
제대로 작업하셨다면 아래와 같은 화면을 볼 수 있습니다.

위의 내용까지는 프로젝트를 만드는 과정이었습니다.
이제부터는 ios 위에 올려야 하는 작업입니다.
우선 Unity에서 File -> Build Settings를 클릭합니다.

다음으로 Platform에서 iOS를 선택한 뒤 Switch Platform을 눌러 플랫폼을 변경해줍니다.

플랫폼이 정상적으로 변경되었다면 Player Settings를 클릭합니다.
이후 Other Settings에서 Bundle Identifier을 변경해줍니다. 저의 경우 com.sidongmen.cardboard로 하였습니다.
Scripting Runtime Version은 .Net 4.x Equivalent 로 설정해줍니다.
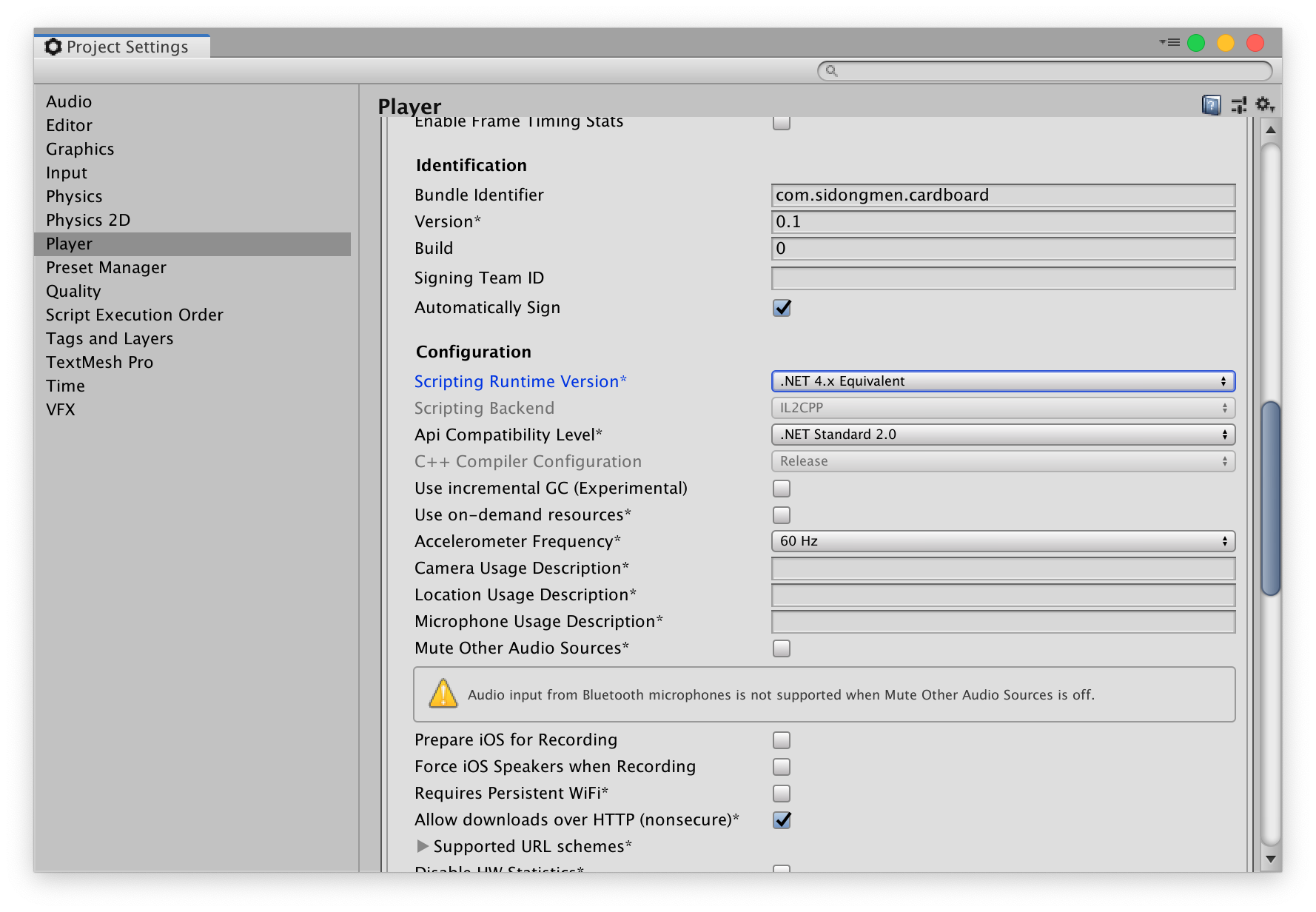
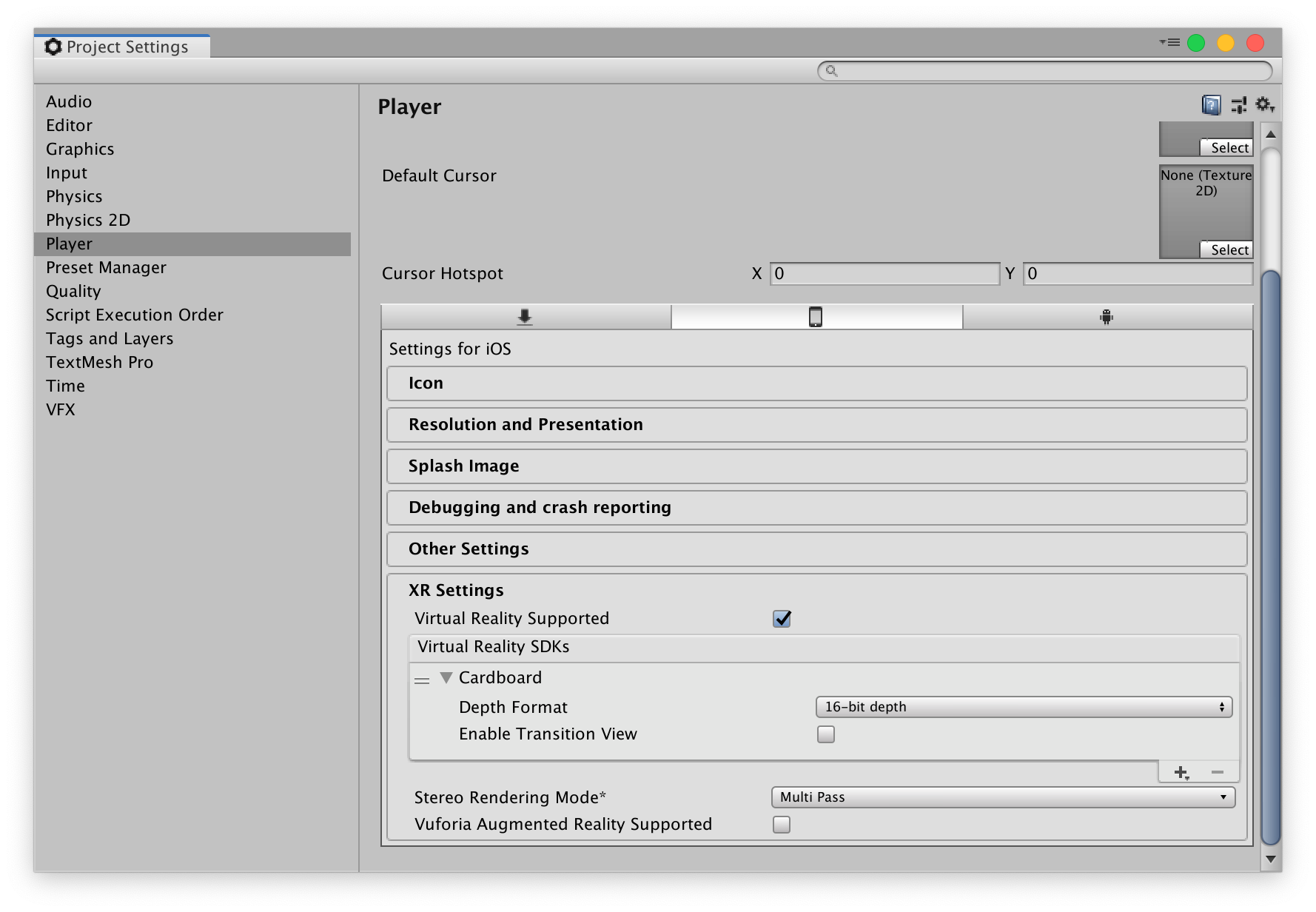
다음으로 XR Settings 탭에서 Virtual Reality Supported 를 체크해줍니다.
우리는 Cardboard에서 사용할 것이므로 Cardboard를 추가해줍니다.
이 작업을 건너 뛸 경우 xcode에서 빌드 시 에러가 발생하니 주의하세요.
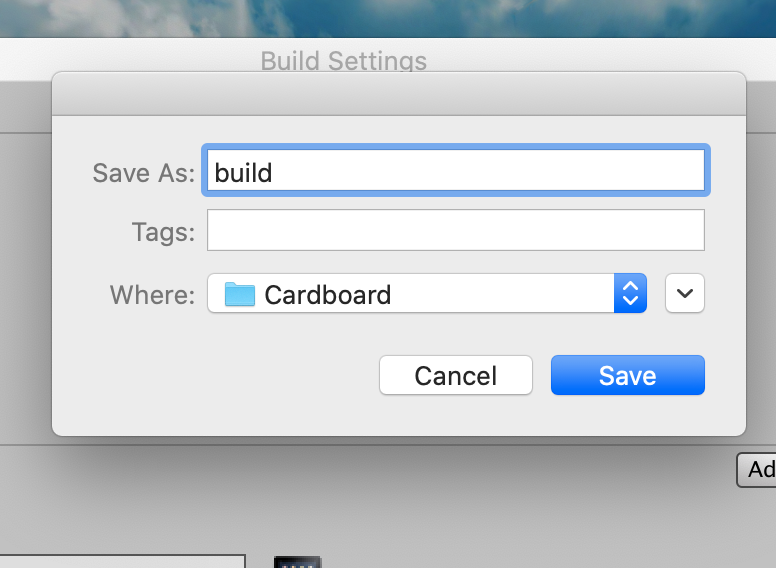
다음으로 아까 열었던 Build Settings에서 Build 버튼을 눌러줍니다. 폴더명을 build로 해주고 Save를 눌러줍니다.

다음으로 xcode를 열어줍니다.
xcode가 없으시면 설치해주세요. 따로 설치방법은 올리지 않겠습니다..ㅎㅎ

xcode를 실행한 뒤 아까 생성했던 build 폴더에 들어가 .xcworkspace 라는 확장자를 가진 프로젝트 파일을 열어줍니다.
xcodeproj가 아니라 xcworkspace입니다!! 헷갈리면 빌드가 안되니 주의하세요!

정상적으로 프로젝트를 열었다면 아래와 같은 화면을 보실 수 있습니다.

이제 USB와 아이폰을 연결해줍니다.
아래와 같은 알림창이 뜨면 신뢰를 눌러줍니다.

제 iphone 이름은 Miley입니다.
xcode에서 디바이스가 인식되었음을 알 수 있습니다.

이대로 상단에 있는 플래이 버튼을 눌러 빌드를 진행하면 Signing 오류가 발생합니다.
프로젝트를 눌러 Signing & Capabilities 탭에 들어갑니다.

Automatically manage signing을 체크하여 계정을 설정해줍니다.
개발자 계정의 경우 매년 129,000원 정도를 지불해야 합니다.
굳이 앱스토어에 올릴 게 아니고 내 디바이스에서 테스트를 할 것이니 가입비를 지불하지 않고
개인 계정을 사용하여 테스트 할 수 있습니다.
저는 개발자 계정을 사용하지 않고 개인 계정을 사용하였습니다.
개인 계정을 추가하는 방법은 아래링크를 참고해주세요.
www.egovframe.go.kr/wiki/doku.php?id=egovframework:hyb3.5:hrte:runiphone
egovframework:hyb3.5:hrte:runiphone [eGovFrame]
아이폰의 경우 iOS7이상에서는 애플 개발자계정없이도 애플계정으로 아이폰에 빌드할수 있도록 변경되었다. iOS 7.0 이상 설치된 아이폰 Xcode에 아이폰의 애플계정이 등록되어야 한다. 보안인증이
www.egovframe.go.kr
개인 계정을 아래와 같이 설정해줍니다.

이제 다시 플레이 아이콘 버튼을 눌러 빌드를 진행해줍니다.
빌드 시 Could not launch 권한 에러가 발생할 경우
아이폰에서 설정 -> 일반 -> 기기 관리를 눌러 해당 앱의 권한을 허용해줍니다.
앱이 잘 설치되었음을 알수 있습니다.


앱을 실행해보았습니다. 잘 작동하네요 ㅎㅎ

교수님께서 나누어 주셨던 Cardboard를 사용해보았습니다.

잘 작동하는 것을 확인했습니다.
네.. 이렇게 xcode를 통해 아이폰용 Unity 를 빌드하는 법을 알아보았습니다.
설명이 미흡한 부분 죄송합니다 ㅠㅠ
쭉 빌드를 해보니 아래에 해당하시는 분이면 안드로이드를 사용하시는게 좋을 듯합니다.
1. 맥북이 없다 (<- 이건 대체가 불가능)
2. 아이폰이 너무 구형이다.(저의 경우 iphone6)
3. xcode를 다뤄본 경험이 많지 않음.
네 뭐 그렇습니다..
긴글 읽어주셔서 감사합니다.
sidongmen - Overview
Be creative. sidongmen has 4 repositories available. Follow their code on GitHub.
github.com
'전공 공부 정리' 카테고리의 다른 글
| MySQL 전공 정리-(1) (0) | 2020.04.28 |
|---|---|
| Computer Network[06] - connection-oriented transport: TCP (0) | 2020.03.30 |
| Computer Network[05] - principle of reliable data transfer(2) (0) | 2020.03.25 |
| Computer Network[04] - principle of reliable data transfer(1) (0) | 2020.03.23 |
| Computer Network[03] - connectionless transport : UDP (0) | 2020.03.22 |








































